





Redmineのデータを直接SQLで操作したいと思ったことはありませんか?
しかし、データベースの論理構造を理解していないと、どのテーブルをどう結合すればいいのか分からず、思うようにデータを抽出できません。
そこで今回、Redmineのチケット管理に関わるテーブルに絞ったER図を作成しました。ER図は、データベースの論理構造を可視化するもので、各テーブルの役割やリレーションがひと目で分かるようになります。
この論理構造を把握しておくことで、SQLの記述がスムーズになり、必要なデータを適切に取り出せるようになります。ワークフローやWiki関連のテーブルは割愛し、チケット管理に関わる部分にフォーカスしています。
作図には「A5:SQL Mk-2」を使用しています。
チケットに関係する部分のER図
ER図を次に示します。プロジェクト情報を格納する「projects」、ユーザーの「users」、チケットの「isses」に薄黄色の背景色をつけました。
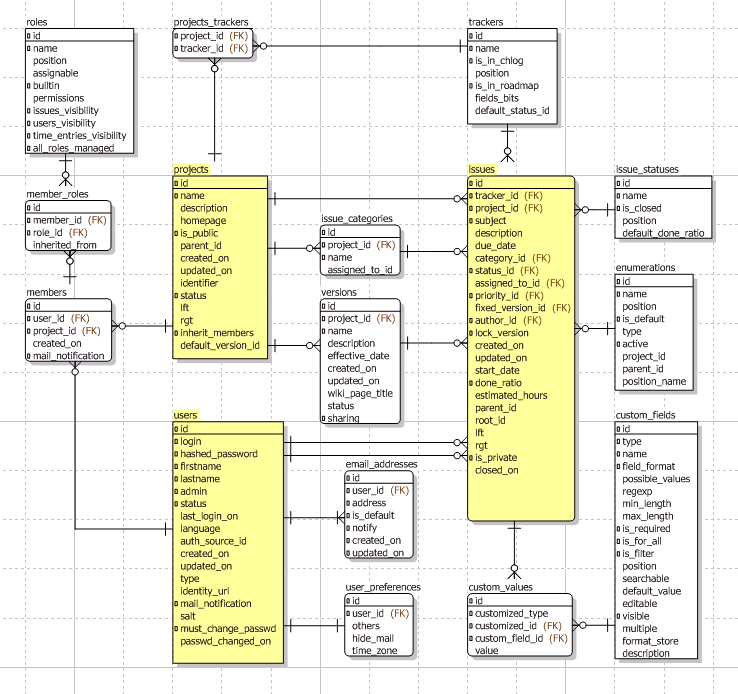
ER図の解説
チケットの基本的な情報は、すべて「issues」テーブルに保存されます。
これは、チケットのタイトルや説明、作成日、担当者などの標準フィールドを持つ、Redmineの中心的なテーブルです。
一方で、カスタムフィールドについては、データが別のテーブルに分かれています。
カスタムフィールドの設定(どんな項目があるか)は「custom_fields」に、そして実際に入力されたカスタムフィールドの値は「custom_values」に保存されます。
また、チケットには「どのプロジェクトに属するか」「どのカテゴリか」「どのバージョンか」「現在のステータスは?」といった情報がありますよね。
これらは、「issues」の中にID(一意の識別子)として保存されていて、それぞれの詳細情報は別のマスター(テーブル)に記録されています。
例えば、
- プロジェクト情報 → 「projects」
- カテゴリ情報 → 「issue_categories」
- バージョン情報 → 「versions」
- ステータス情報 → 「issue_statuses」
IDのフィールドと、そのマスターの一覧は次の通りです。
| テーブル名 | フィールド名 | マスター(テーブル) |
|---|---|---|
| issues | tracker_id | trackers |
| project_id | projects | |
| category_id | issue_categories | |
| status_id | issue_statuses | |
| assigned_to_id | users | |
| priority_id | enumerations | |
| fixed_version_id | versions | |
| author_id | users | |
| parent_id | (issues) | |
| root_id | (issues) | |
| custom_values | customized_id | (issues) |
| custom_field_id | custom_fields |
まとめ
このように、Redmineのデータは「チケットの基本情報」と「各種マスター情報」に分かれており、IDをキーにして結びついています。
この仕組みを理解すると、SQLを使ってデータを取得しやすくなりますよ!
最後までご覧いただきありがとうございます。
では、また。


